
In Part 1: about OGC Open Routing API, we built a Routing engine using an Open API. In Part 2: Skymantics’ Universal Routing Engine (SURE), we described the architecture of Skymantics’ Universal Routing Engine, and the different blocks of the engine and their function. In this final post of the series, we are going to review several tips and tricks on how to build an effective routing engine.
There are two trade-offs that need to be carefully balanced: accuracy vs. performance. It is useless for a routing engine to quickly generate sub-optimal routes, but it is equally impractical to generate optimal routes that require a long time to compute. The first critical point to look at in the routing engine is the routing algorithm.
Routing Algorithms
Skymantics has experimented with shortest-path algorithms, in particular Dijkstra and A* (A-star), in three modes: unidirectional, bidirectional, and with Contraction Hierarchies optimization (CH). Implementing a unidirectional, vanilla-version of these algorithms is fairly simple, and there are plenty of tutorials on the Internet to help understand how to do so. As a rule of thumb, building bidirectional algorithms (in other words, the path is calculated simultaneously from both origin and destination) will provide the optimal route 5x to 10x faster than unidirectional, even though choosing the optimal joint node (where the path from the origin meets the path from the destination) has its own issues. However, choosing between Dijkstra and A* and between bidirectional or with CH is not simple.
When to use A*
In theory, A* should be a more efficient algorithm, as it requires less computations: it is basically a directed Dijkstra that only takes into consideration the graph nodes that help moving in the direction towards the destination. However, this requires calculating direction and heuristic distances which is a more costly computationally operation than a Dikjstra iteration, and it may be counterproductive. In general, for very dense meshes of streets/roads of the same hierarchy, A* may be a better choice. For all the rest, Dijkstra will probably be sufficient.
When to use CH
For long, cross-country routes, you need some kind of optimization such as Contraction Hierarchies. This optimization will prioritize higher hierarchy routes and will ignore low hierarchy alternatives, dramatically reducing the computations to find the shortest route very efficiently. Here is an example of a 265 km (165 miles) route crossing Belgium: it takes 35 seconds to calculate with Dijkstra bidirectional algorithm, but only 0.1 seconds using the Contraction Hierarchies optimization.
When to use Bi-direction Dijkstra
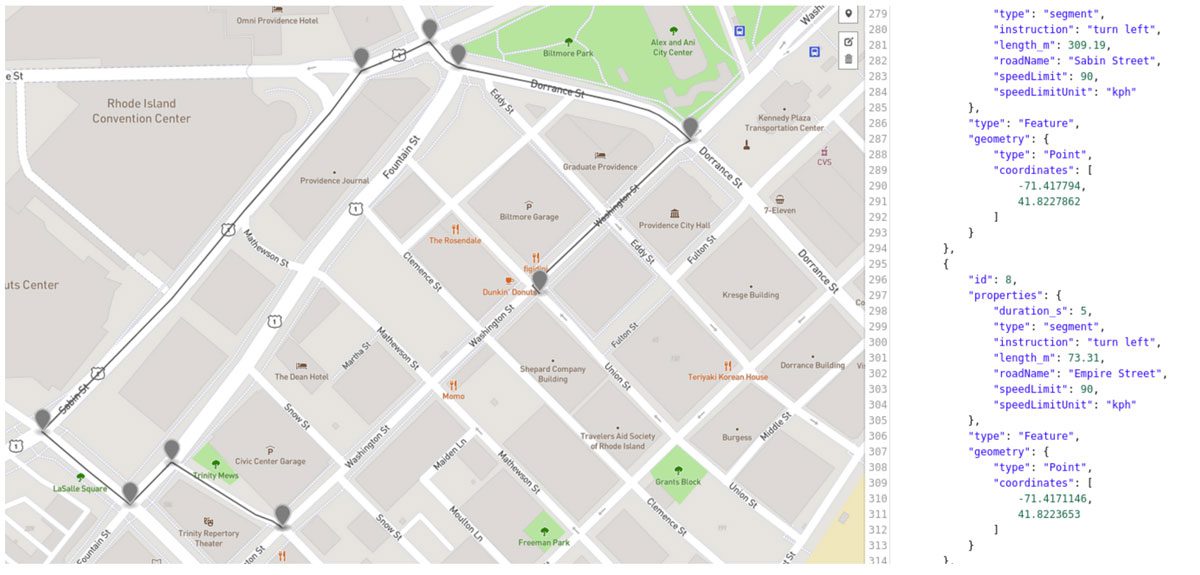
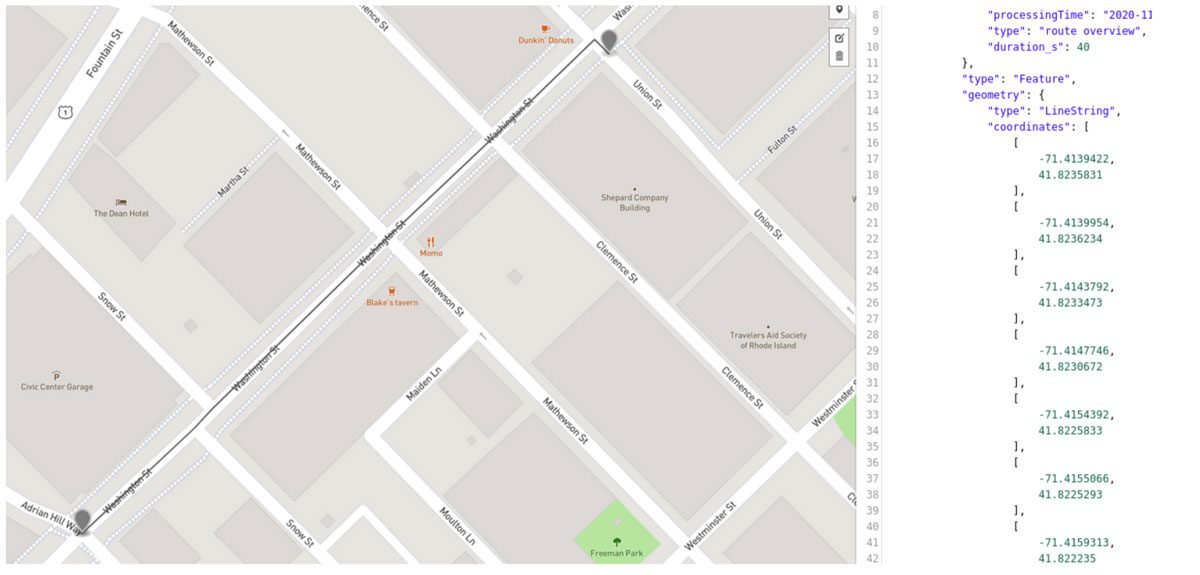
For shorter, urban routes, Contraction Hierarchies might result in a sub-optimal route, as the algorithm can take detours if it finds a higher hierarchy route nearby. It is possible to reduce this effect or even remove it completely by carefully tweaking the road hierarchies and to allow the algorithm a few additional iterations. But if the routing application is just for a specific urban area, it may be simpler to just use a bidirectional Dijkstra. Here is an example of a route in downtown Providence, Rhode Island, that should be just a straight line, but that Contraction Hierarchies gets fooled and takes a detour through the nearby main street. The computation time for CH is 1 millisecond vs 1.5 milliseconds for bidirectional Dijkstra, demonstrating there is leeway for additional iterations to avoid this detour effect.
Routing algorithms can guarantee accuracy and improve performance to a certain degree. The truth is they route through a mesh of roads that are defined in a map dataset, and the results depend heavily on the accuracy of these datasets and the way in which they were preprocessed.
Preprocessing Datasets
Datasets and preprocessing are the single most important way to improve the accuracy and performance of a routing algorithm. It is difficult to stress this point enough. I will try to summarize the main aspects to take into account in the following points:
Not all datasets have the same level of accuracy. Open Street Maps is a great example; it covers practically the whole world is free to download and use, but it lacks some important information such as many speed limits, height/weight limits, or forbidden maneuvers. In some cases, it may even contain false information with regards to one-way street directionality or connections, to name a couple. Other maps, such as HERE, offer a much better level of accuracy, but come with a cost. Funny enough, street coordinates do not match 100% among different datasets and you may discover that the same coordinates are considered part of different streets depending on the dataset you use.
Depending on the application of your routing engine, many street or road segments provided in a dataset can be merged together into a single edge, sometimes reducing the size of the graph by up to 90%. For example, shortcuts can be created to jump over intersections of lower hierarchy, accelerating the route calculation on long distances.
A critical part of the preprocessing is deciding how to classify the hierarchy of road links: are they linking lower to higher hierarchy roads? Are they linking the same hierarchy roads? This is a particularly important aspect for motorway junctions, since roads linking motorways must have the highest hierarchy (to speed up Contraction Hierarchies), but setting all road links from a motorway to the highest hierarchy will slow down the calculations due to too many intersections.
Routing algorithms and datasets & preprocessing are the key aspects to consider in building an accurate and performant routing algorithm. But there are other aspects that can make the difference between a useful and a useless routing engine.
Programming Best Practices
I will take for granted that good programming practices are in place, and that an appropriate programming language is chosen for the task. There are three critical points to consider when deploying and operating a routing engine:
- Graph data must reside in memory for maximum performance. There might be some parts in a database, for example geographical data to help finding the closest nodes to origin and destination, but the routing algorithm needs to operate with in-memory data, or it risks to underperform for maps slightly bigger than a town center.
- The routing engine must pre-load all required data and must make use of threading for secondary, time-consuming tasks, such as saving the generated route to the disk. Otherwise, these times will add up, reducing the overall performance.
- This might seem obvious, but if the routing engine is to be offered as a remote service, the connection speed will be crucial. There is no point in speeding up the routing calculation if the bottleneck is in the communication channel. Latency and throughput are essential to a performant API service.
And that’s basically it. Building a routing engine can be an exciting task, full of challenges and fun. Even if your goal is not to build one, but you need to use routing intensively, it is good to understand its key aspects. I hope you had as much fun reading these series of articles as I had writing them. Cheers!
Would you like to learn more?
Feel free to Contact Us, we’ll be happy to help!